Arquitectura de raspado de web para extracción de datos escalable

Aloísio Vítor
Image Processing Expert
TL;DR
- El raspado web en Rust funciona mejor cuando las operaciones de obtención, análisis, renderizado y almacenamiento están separadas en capas distintas.
reqwestyscrapercubren muchos objetivos estáticos con un menor costo de recursos y mantenimiento más limpio.- El raspado asíncrono con Tokio mejora el rendimiento para cargas de trabajo basadas en E/S, pero aún requiere límites de tasa, reintentos y control de cola.
- El raspado con navegador en modo headless debe ser un recurso de último recurso para páginas renderizadas con JavaScript, en lugar de la ruta predeterminada.
- La protección contra bots, la rotación de proxies y los eventos CAPTCHA deben manejarse con políticas claras y diseños de automatización compatibles.
- Para flujos de automatización legítimos que cumplan con una necesidad real de negocio, CapSolver puede integrarse en una capa de último recurso estrecha siguiendo su flujo de API oficial.
El raspado web en Rust es más efectivo cuando se diseña como una arquitectura, no como un solo script. Este artículo está dirigido a ingenieros, equipos de datos y operadores técnicos que necesitan extracción confiable a gran escala. La conclusión principal va primero: los mejores sistemas de raspado web en Rust mantienen el camino rápido simple con reqwest y scraper, y agregan el raspado asíncrono, el raspado con navegador en modo headless, la rotación de proxies y el manejo de desafíos solo cuando el objetivo realmente los requiera. Esta estructura reduce los costos, mejora la estabilidad y hace que los pipelines de ejecución prolongada sean más fáciles de observar.
Visión general del raspado web en Rust
El raspado web en Rust es una buena elección para trabajos de extracción grandes porque combina seguridad de memoria con un rendimiento predecible. Estas cualidades son importantes cuando un trabajador puede procesar miles de páginas, analizar marcado inestable y escribir registros normalizados durante horas.
La mayoría de los artículos en los resultados de búsqueda explica cómo obtener una página y analizar un selector. Este material es útil, pero raramente responde a la pregunta más difícil. ¿Cómo debe verse la arquitectura completa de raspado web en Rust cuando se necesitan resiliencia, observabilidad y espacio para escalar?
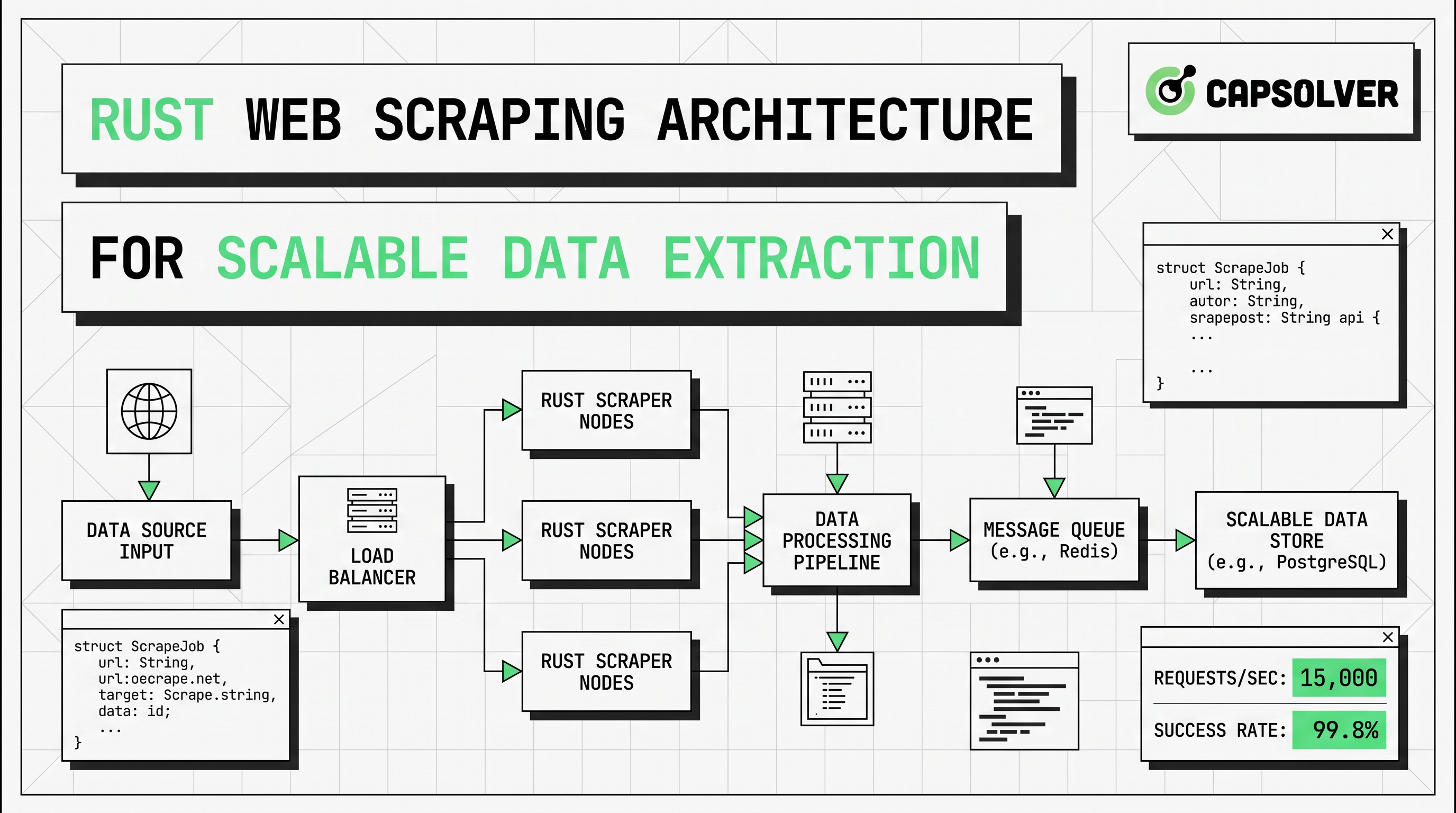
Un diseño de producción suele necesitar una capa de obtención HTTP, una capa de análisis, una rama de renderizado para páginas de JavaScript, una capa de almacenamiento y una capa operativa para reintentos, métricas y ritmo de solicitudes. El orden correcto también es importante. Comience con el camino más barato primero. Obtenga HTML crudo. Analice solo los campos que necesita. Escalé a raspado con navegador en modo headless solo cuando el HTML del servidor no contenga los datos objetivo. Agregue rotación de proxies solo cuando sea necesario la distribución de tráfico o el acceso regional. Agregue manejo de CAPTCHA solo cuando un flujo de automatización compatible tenga una razón válida para continuar.
Para equipos que planean estos límites, crawling y raspado web ayuda a aclarar el alcance, y cómo extraer datos estructurados es una lectura útil antes de comenzar el mapeo de campos.
Bibliotecas principales para el raspado en Rust
El raspado web en Rust generalmente comienza con tres bloques de construcción: reqwest, scraper y Tokio. La documentación oficial de reqwest describe reqwest como un cliente HTTP de nivel superior con soporte asíncrono, cookies, redirecciones, TLS y soporte para proxies. Eso lo hace una capa de transporte práctica para el raspado web en Rust.
La tutorial oficial de Tokio explica por qué las futuras y el modelo de ejecutor se ajustan a cargas de trabajo de E/S de alta concurrencia. Eso importa porque el raspado web en Rust pasa la mayor parte de su tiempo esperando servidores remotos en lugar de quemar CPU en cálculos locales.
Solicitud HTTP con reqwest
reqwest debe estar en la capa de transporte. Reutilice un cliente único por trabajador o grupo de trabajadores. Eso mantiene el agrupamiento de conexiones efectivo y le da un lugar único para definir encabezados, tiempos de espera, cookies y política de proxies.
rust
use reqwest::Client;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::builder()
.user_agent("Mozilla/5.0")
.build()?;
let html = client
.get("https://example.com")
.send()
.await?
.error_for_status()?
.text()
.await?;
let document = Html::parse_document(&html);
let card = Selector::parse("article")?;
for node in document.select(&card) {
println!("{}", node.text().collect::<Vec<_>>().join(" "));
}
Ok(())
}Este patrón mantiene el raspado web en Rust eficiente en páginas estáticas. También hace que el manejo de errores sea más fácil de estandarizar. Las comprobaciones de estado, los presupuestos de reintentos y los registros estructurados pueden vivir alrededor de la capa de solicitud en lugar de mezclarse en el código del analizador.
Análisis HTML con scraper
scraper pertenece a una capa de análisis que permanece pequeña y testable. No mezcle selectores con lógica de red si espera que los modelos cambien. Un analizador sólido acepta HTML crudo y devuelve registros tipados, registros parciales o un error claro de extracción.
Esta separación importa porque el desplazamiento de selectores es común. Los nombres de clase cambian. El texto se mueve a atributos. Nodos decorativos aparecen entre elementos objetivo. En el raspado web en Rust, la aislación del analizador hace que estos fallos sean visibles en las pruebas antes de que todo el pipeline comience a escribir datos incompletos.
Arquitectura de raspado asíncrono
El raspado asíncrono es una de las principales razones por las que el raspado web en Rust puede escalar bien en infraestructura modesta. El runtime no hace que los sitios web respondan más rápido. Hace que los trabajadores sean más eficientes mientras muchas solicitudes esperan en la red o en la respuesta del origen.
Un pipeline de raspado web en Rust escalable suele seguir la estructura siguiente.
| Capa | Rol | Predeterminado de Rust | Principal riesgo |
|---|---|---|---|
| Programador | Elige URLs y prioridad | cola o canales | tráfico estallido |
| Recuperador | Envía solicitudes HTTP | reqwest::Client |
403, 429, tiempo de espera |
| Analizador | Extrae campos | selectores de scraper |
cambio de plantilla |
| Renderizador | Carga páginas JS | raspado con navegador en modo headless | costo de CPU y memoria |
| Capa de desafío | Maneja eventos CAPTCHA permitidos | servicio de respaldo de CapSolver | tipo de tarea incorrecto |
| Almacenamiento | Escribe salida normalizada | JSON, CSV, DB | discrepancia de esquema |
| Observabilidad | Rastrea salud y calidad | registros, seguimiento, métricas | pérdida de datos silenciosa |
La regla de diseño clave es la escalada selectiva. Comience cada objetivo en el camino de bajo costo. Si el HTML devuelto ya contiene los datos, permanezca con reqwest y scraper. Si los campos objetivo solo aparecen después de la hidratación, renderizado del lado del cliente o eventos del navegador, redirija solo ese tipo de página al raspado con navegador en modo headless. Si aparecen controles de protección de bots o verificaciones CAPTCHA dentro de un flujo aprobado, redirija solo esos eventos a una rama de respaldo estrecha.
Este es el punto donde muchos sistemas se vuelven ineficientes. Los equipos predeterminan el automatismo del navegador para cada solicitud. Eso aumenta los costos, reduce la concurrencia y hace que los fallos sean más difíciles de clasificar. El informe State of JavaScript de HTTP Archive muestra que las páginas modernas siguen dependiendo mucho de JavaScript, con un tamaño medio de transferencia de JavaScript de 803,3 KB y 23 solicitudes de script externas en la vista del informe seleccionado. Esto explica por qué algunos objetivos necesitan renderizado, pero no justifica usar navegadores para cada página.
Manejo de páginas renderizadas con JavaScript
El raspado con navegador en modo headless es necesario cuando los datos se crean después de la respuesta HTML inicial. Las señales comunes incluyen HTML del servidor vacío, contenido inyectado después de la hidratación, listas de desplazamiento infinito o páginas que revelan campos solo después de la interacción del usuario.
El raspado web en Rust debe tratar el renderizado del navegador como una rama separada en lugar de un punto de partida universal. Úselo para cuadrículas de productos que se llenan después de las solicitudes del cliente, dashboards renderizados en el navegador o interfaces donde el contenido clave está oculto detrás de clics y lógica de desplazamiento. Mantenga el grupo de navegadores pequeño y aíslelo de sus trabajadores HTTP asíncronos principales.
Una regla de decisión práctica es simple. Si los datos están presentes en el HTML crudo, permanezca con reqwest y scraper. Si los campos aparecen solo después de la ejecución de JavaScript, mueva esa ruta al raspado con navegador en modo headless. Si el mismo objetivo también aplica controles de protección de bots, revise juntos la política de red, el comportamiento del navegador y los requisitos de respaldo en lugar de parchearlos uno por uno.
Para lectura interna relacionada, automatización de navegadores para desarrolladores y automatizar la resolución de CAPTCHA en navegadores en modo headless encajan naturalmente en este modelo de capas.
CAPTCHA y limitaciones de raspado
El raspado web en Rust siempre tiene límites. Algunos son técnicos. Otros son legales u operativos. El lado técnico incluye reputación de IP, manejo de sesiones, verificaciones de huella digital del navegador, APIs ocultas y protección de bots por capas. El lado operativo incluye ritmo de solicitudes, presupuestos de errores y impacto del tráfico en el sitio objetivo.
Por eso, la conformidad debe integrarse en la arquitectura. La guía de robots.txt de Google Search Central explica que robots.txt se usa principalmente para gestionar el tráfico de los crawlers y evitar sobrecargar los sitios. Este punto importa para el raspado web en Rust porque un sistema bien diseñado no solo intenta extraer datos. También intenta controlar la carga, reducir las solicitudes innecesarias y mantener el comportamiento de recolección razonable.
Cuando los flujos de automatización legítimos encuentran pasos CAPTCHA, CapSolver es relevante como un servicio de respaldo enfocado. La forma más segura es seguir la documentación oficial en lugar de inventar formatos de solicitud personalizados. La documentación de createTask de CapSolver muestra el patrón estándar de cuerpo de solicitud a continuación.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"TU_CLAVE_DE_CLIENTE",
"appId": "ID_DE_APLICACIÓN",
"task": {
"type":"ImageToTextTask",
"body":"IMAGEN_EN_BASE64"
}
}El mismo flujo oficial devuelve un taskId para tareas asíncronas, que luego debe verificarse a través de getTaskResult. En un sistema de raspado web en Rust escalable, esa lógica de desafío debe permanecer fuera del camino estándar de obtención y análisis para que las solicitudes normales permanezcan rápidas y fáciles de monitorear.
Redime tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización de inmediato!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional de bonificación en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
Escalando raspadores de Rust para recolección a gran escala
Escalar el raspado web en Rust se trata principalmente de control, no de volumen de código. La arquitectura debe imponer concurrencia por dominio, techo de reintentos, presupuesto de tiempo de espera y validación de salida. Sin estos controles, trabajadores más rápidos simplemente crean fallos más rápidos.
La rotación de proxies pertenece a la capa de transporte en lugar de la capa de análisis. Úsela cuando las solicitudes necesiten distribuirse a través de direcciones IP para equilibrar la tasa, acceso regional o aislamiento de carga de trabajo. Mantenga la política específica. Rotéela por dominio, clase de endpoint o tipo de carga de trabajo. Evite el cambio aleatorio de proxies que rompa la continuidad de la sesión y agregue ruido al depurado.
También es aquí donde los recursos de apoyo internos se vuelven útiles. Servicios de proxies mejores pueden ayudar a evaluar la estrategia de red, mientras que legales de raspado web es un punto de verificación interno útil antes de expandir el volumen de recolección.
Los sistemas de raspado web en Rust más sólidos también miden directamente la calidad de la extracción. Rastree la tasa de éxito, la tasa de campos vacíos, el desplazamiento de selectores, la proporción de renderizado, la latencia media de obtención y el costo por registro exitoso. Estas métricas muestran cuándo un camino HTML estático aún es suficiente y cuándo el raspado con navegador en modo headless, la rotación de proxies o el manejo de desafíos se está volviendo demasiado costoso.
Resumen de comparación
| Enfoque | Caso de uso ideal | Perfil de costo | Perfil de confiabilidad | Notas |
|---|---|---|---|---|
reqwest + scraper |
páginas estáticas o ligeramente dinámicas | bajo | alto cuando los selectores son estables | mejor predeterminado para el raspado web en Rust |
| Raspado asíncrono con trabajadores Tokio | muchas URLs basadas en E/S | bajo a medio | alto con límites de tasa | mejora el rendimiento, no la calidad del analizador |
| Raspado con navegador en modo headless | páginas renderizadas con JavaScript | alto | medio | aíslelo en un pequeño grupo |
| Rotación de proxies | control de tasa distribuido y acceso geográfico | medio | medio | útil cuando la identidad del tráfico importa |
| Servicio de respaldo de CapSolver | eventos CAPTCHA permitidos en flujos de automatización | basado en eventos | medio a alto | mantenga la implementación alineada con la documentación oficial |
Conclusión
El raspado web en Rust escala cuando la arquitectura permanece selectiva. Use reqwest y scraper para el camino rápido. Agregue raspado asíncrono cuando necesite más rendimiento en trabajos basados en E/S. Reserve el raspado con navegador en modo headless para páginas que realmente necesiten renderizado. Mantenga la rotación de proxies y el manejo de desafíos como capas de respaldo controladas. Este diseño mantiene los costos más bajos, mejora la observabilidad y hace que el mantenimiento del analizador sea mucho más fácil.
Si su pipeline actual envía cada página a través de un navegador, la mejora más limpia suele ser un dividir el camino. Mueva los objetivos estáticos de vuelta a HTTP simple. Mantenga las páginas de JavaScript en una rama de renderizado más pequeña. Mantenga la lógica de desafío aislada. Ese cambio solo suele mejorar la confiabilidad y la economía de unidad.
Preguntas frecuentes
¿Es mejor el raspado web en Rust que en Python para trabajos grandes?
El raspado web en Rust suele ser una buena elección cuando la estabilidad a largo plazo, la concurrencia y la seguridad de memoria son más importantes. Python aún tiene un ecosistema más amplio de raspado, pero Rust es atractivo cuando la eficiencia del trabajador y el rendimiento predecible son las prioridades principales.
¿Cuándo debo pasar de reqwest al raspado con navegador en modo headless?
Cambia solo cuando el HTML del servidor no contenga los campos que necesita. Si los datos objetivo aparecen después de la hidratación, eventos del lado del cliente o solicitudes de API retrasadas, el raspado con navegador en modo headless se justifica.
¿Cómo ayuda el raspado asíncrono en Rust?
El raspado asíncrono ayuda al raspado web en Rust a manejar muchas solicitudes en espera con menos recursos desperdiciados. Mejora el rendimiento para E/S, pero aún requiere límites de tasa, lógica de reintentos y pruebas del analizador.
¿Siempre necesito rotación de proxies?
No. Muchas tareas funcionan bien sin él. La rotación de proxies es importante cuando necesitas acceso regional, distribución de tráfico por dominio o menor concentración de tráfico desde un rango de IP.
¿Cómo debo manejar las páginas CAPTCHA en un flujo de trabajo conforme?
Mantén el manejo de CAPTCHA estrecho, documentado y separado de la ruta normal de obtención. Si un flujo de trabajo de automatización legítimo lo requiere, usa el flujo de tareas oficial de CapSolver y mantén la implementación consistente con la documentación publicada.
Ver más
web scrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.

web scrapingFeb 10, 2026
Datos como Servicio (DaaS): ¿Qué es y por qué es importante en 2026
Comprender Datos como Servicio (DaaS) en 2026. Explora sus beneficios, casos de uso y cómo transforma los negocios con insights en tiempo real y escalabilidad.

